Just being a great developer or even a good one is not enough to create a great career. How effective you are at communicating your skills, experience and the value you can bring to others really drives the quality of your career. Luckily there are many ways to show off your skills, including those soft skills that are harder to quantify. It is not just recruiters & human resources departments that can get you a job, but more and more it is other developers that bring you in to their teams. The more developers who know who you are, the more opportunities will be presented to you.
Activities you can do to boost your career include:
- Blogging & technical content
- Social media for research and communication
- digital presence
- Meetups, Conferences and public speaking
- Understanding the modern recruitment process
I will walk through this aspects to help you understand them in more detail and describe my experiences and any tips I have to share
Previously I covered aspects of creating your digital self previously, covering a range of social media and developer community websites.
Classic recruitment
Most of the recruitment companies out there are not particularly progressive, essentially providing little more than collecting and shuffling CV’s. These types of recruiters are solely focused on their own goals and you are just a name in their database.
We will look at why these recruiters are considered evil and why community engaged recruiters are often a much better service.
Evil recruiters
While recruiters themselves are typically not evil, the system that they work within makes them seem so. Most recruitement consultancies are all about the numbers, usually leaving a bad experience for all involved.
Typically these recruitement companies engage with their clients (employers) to deliver results based on numbers (eg. 20 CV’s within 5 working days). This leads to brute-force searches of all the CV’s they have collected for any relevant keywords for a particular job specification.
If not enough results are found, then recruitment consultants will carry out similar brute-force searches on LinkedIn and Github to try and find possible candidates. These searches are sometimes also used to find people who do not have a CV on file with the company.
Deailing with Evil recruiters
It may still be worth dealing with a specific recruitment consultancy if they have the sole contract for a particular company you are interested in working with.
I suggest that you send your CV as a pdf document to ensure that recruitement consultancy does not edit the document. If they insist on a word document, include a reference to an online version and place it in a prominent place on your website (should the employer Google who you are).
Companies such as RecWorks & eSynergy Solutions actively engage with technical communities in order to understand more effectively how the developer role continues to evolve. Typically these companies deal with more forward thinking companies that have more progressive roles.
They will probably not cover as wide a scope as evil recruiters, however it is usually a case of quality over quantity.
These community engaged recruiters usually have a better relationship with you and are more open with their processes. They also give back to the community and are in a better position to understand the trends in our industry.
The modern recruitment process
Developers recruit developers
The more enlightened companies realise that developers are much more effective at finding good developers than the classic recruitment process. In fact, many IT organisations and development teams are frustrated by the speed and quality of their own HR process and it can be seen as a blocker.
I have join several companies via initial contact from the development team. Often this is from meeting them at developer events either as an attendee or a speaker. I also get recognition from blog posts.
Developer team recruitment practices
Pairing
By spending a day with the company is a very effective way for them to understand what it will be like working with you. It also gives you a great experience of what it would be like working with their developers.
You may pair with one person all day, however its preferably to pair with different people during the day.
My first experience with this was at a company that built online games. They effectively hired me for 2 days as the recruitment process. On paper it looked a great match and the first couple of hours were all positive. However, as we got into the detail of what they were doing I grew concerned about their approach and didnt feel like I would be a good cultural fit. In the end we parted after the first day as both sided realised it was not a great match. I gained many interesting insights into how I think that day, which made it easier for me to assess any other potential roles.
Tests / Challenges
I am weary of tests that do not let you access the Internet for answers. Shutting you away from the tools you use regularly only testing your memory and not your ability to apply what you can learn. Everyone writes code with the help of Google, Stack Exchange, etc and there is just too much to remember and from my point of view its more important to see how we can learn something new and apply it.
Instead, setting a challenge and building it with a candidate is much more effective. Having an exercise or challenge that you have recently done at work it a very valuable approach at it also lets the candidate understand the team they will be working with a little more. There are also many kata-style challenges on the Internet to choose from if you cant come up with your own exercises.
Some companies will even publish how to approach them via Github, eg Vzaar, a video hosting company publishes a note to recruiters
Preparing for tests
Its very common for you to be sent a coding challenge, so one way to improve your chances it to practice similar kinds of challenges. Most sane challenges will probably be similar to one of the many coding kata challenges. Many of these are published on the Internet and if you get really stuck you may be able to find some suggested solutions (but its more effective to do as much as you can first).
Another excellent way is to attend a code dojo, usually a couple of hours on an evening where you get into small groups and code up a challenge. At the end you demonstrate what you have done, covering any challenges and lessons learned. Code dojos are always welcoming to new starters and its a very collaborative event, all you need is a willingness to try.
Examples of code dojo events include
If you want to start you own Code Dojo, take a look at “How to run an awesome code dojo“ by Nicholas Tollervey.
Showing your development skills
By making the applications you build available via the Internet, with services like [Heroku], enables anyone to see what you can do and a chance to experience your work. Think of this like an artist or model creating a portfolio of work.
Actually having people use your work is a very powerful way to get attention. If the developers you meet have used your apps then they will give you a lot of trust and have plenty of questions to ask you about, on a subject that you should be fairly comfortable with.
If user experience (UX) is not your strongest area (and you dont want to create just another Twitter bootstrap site), then you can create a [webservice] or [API]. or that is either very useful or very funny (but be careful to not offend here).
Examples of an API….
- Google Map API
- KeanIO Analysis in 60 seconds (check mobile browser tab)
- Twilio - set up your own service to respond to phone calls & texts
- Braintree - add a payments system to your app
- Pusher - add websockets service to your app
There are hundreds more you can find on Google or go to any hackathon event and the sponsors usually have API’s you can try out.
Hackathons
Another way to create something different is to take part in a Hackathon. This is typically a weekend event where you have 24-36 hours to create something, usually as a small group (eg. 2-6 people). Each group builds a web app, a mobile app or even something physical connected to a software service or app. At the end of the hack each team usually has a few minutes to show off what they have built.
Many hackathons have prizes for the teams they judge the best. Event sponsors have their own prizes that they give out prizes for the team they like the most. Prizes can range from cool gadgets & toys to large cash prizes. Because of prizes, there is more of a competition aspect to some hackathons, however, most remain collaborative regardless of the prizes on offer.
Visit the meetup.com group called Hackathons & Jams that lists many of the events happening in the United Kingdom.
Showing your code

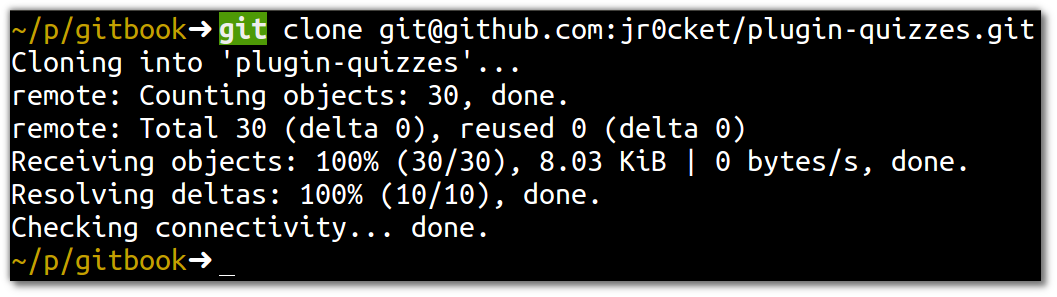
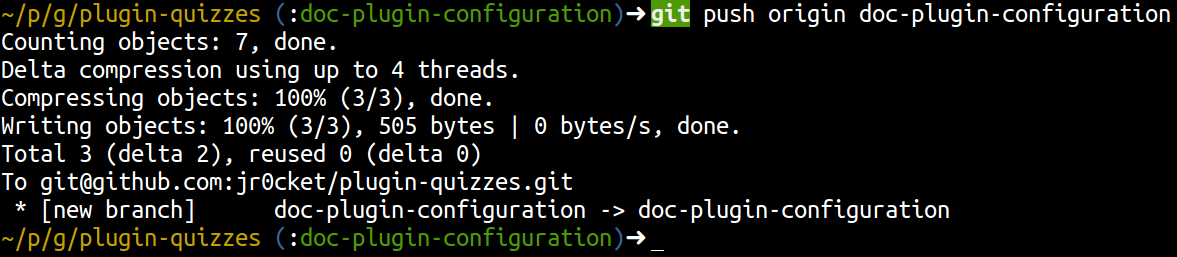
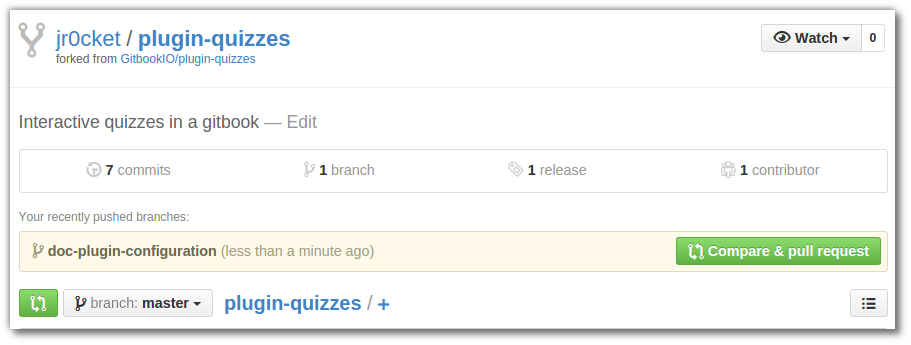
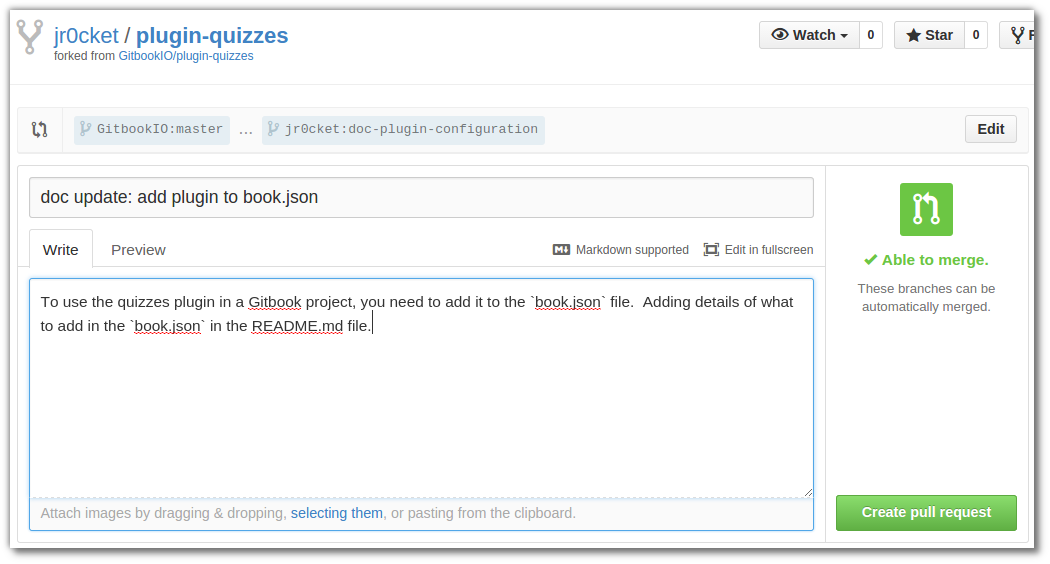
If you want to show how good a developer you are to other developers, then share your code on Github. If you create sometihng interesting then develops may star your project or follow you
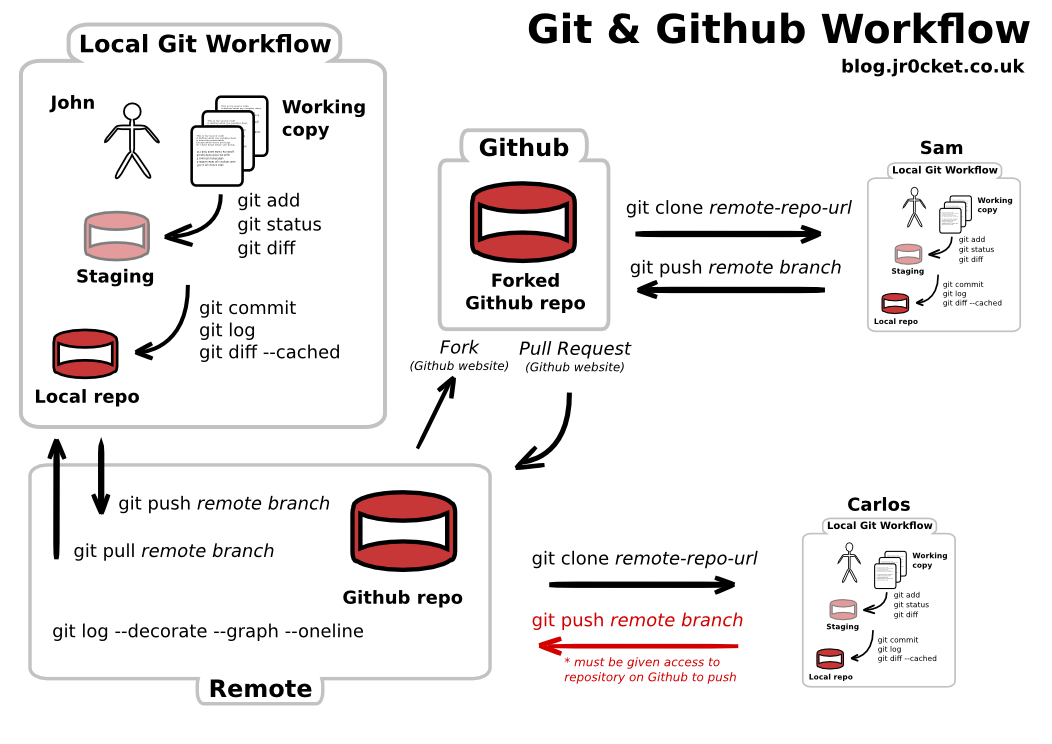
Here are some useful resources if you are still learning Git / Github
Recruitement through Github
Some interesting articles on the subject of recruiting from Github, including details of what recruiters may be looking for include:
Language experiences - Polyglot developers
Once developers have gained solid experience in there first language, many look to enhance their skills by trying a very different language. A common choice is JavaScript, especially for those developers working on web user interfaces or needing to build lightweight services / API’s.
More and more developers are learning a second or third major language, making them what we term Polyglot developers, in that they are comfortable coding with more than one language.
A polyglot developer is very valuable as they can use the most appropriate language for the project at hand. They understand the characteristics of a language and know why that language would be the best fit.
A good starting point for this is by reading Seven Languages in Seven Weeks. This book teaches you the characteristics of seven languages, rather than trying to make you proficient in seven languages.
Contributing to Open Source Projects
Most of the software world now runs on open source software, so there are a great many projects out there you can contribute to. Many of these project can be found on Github
If you are interested in getting involved, choose a project you really like or some software you use often. Check the project README file for details of how to contribute. Projects on Github have a built in Issue Tracker where you can check for bugs that need fixing and any features requested. If you start with one of these issues then let the project team know about it, either in the issue itself or in the chat room if the project has one.
Many projects have IRC, Slack or Gitter based chat rooms to talk about the developent of a project. Introduce yourself and let them know you are interested in helping out.
If you are looking for projects to contribute, talk at look at Your First PR on Twitter.
Open Source Projects usually have a license, defining the terms of use for the software. By UK law, the authors of the sorouce retain copywrite of that software, unless specifically over-ridden by the license. The Open Source Initiative has a list of Open Source licenses
Creative Commons is a similar license usually for creative works such as images, videos, blogs & books
Writing tutorials & blog posts
Writing a tutorials & blog posts are a great way to review how much you understand about a topic. Its also a great way to get feedback from the community, who can offer additional technologies & approached to try out.
A great tool for writing tutorials and ebooks is Gitbook. You can write your content in [Markdown] and Gitbook will generate a fully navigable website and a range of ebook formats.
Helping & Mentoring via StackExchange or forums
There are lots of opportunities to help other developers at websites such as StackExchange. Find a topic you have experience in or even something you are currently learning. There are lots of questions at various skill levels and so there should be some you can answer.
Actually for some questions you can practice Googl’ing for the answer. Its amazing how many answers you can find out there, either in one post or accross a few different posts. You can also help keep StackExchange useful by idenifying duplicate questions.
Speaking at conferences & meetups
Speaking at conferences can seem quite dawnting, but its invaluable experience. If you can talk to an audience of 50 people you can easily talk to your team and the rest of the business you work for.
Obviously speaking at events helps you get noticed and gives you a good standing with employers. When you are speaking you are also helping to promote your employer too, even if you are not directly talking about anything your employer does.
I suggest starting small with a local meetup and giving what is called a Lightning Talk. This is a 5 to 10 minute talk on a specific topic and is a good way to start to build up some confidence.
There are plenty of expert speakers out there, but everyone had to start small and work their way up to bigger talks
Everyone has something they do that is of interest to others, it can be as simple as sharing your experiences of a language feature or new technology.
My first talk was on Personal Kanban, it was an agile technique I had been using for a few months and it had made a big difference to the way I worked. I did a 30 minute talk on the subject and although it felt like hard work and not very good, I got lots of positive feedback from the audience.
Top tips for speaking
Have a point (or three) you want to get across - its good to be focused in your talk, trying to cover too many things in a talk can be quite confusing for an audience.
Tell a story around the point you want to make, as context makes it easier for people to relate and remember your point.
Draw from your own experiences. Nothing is more powerful for an audience than someone sharing their own challenges & solutions.
Practice your talk - either with yourself or with others. If you have a talk for a conference, then get some colleagues together at lunchtime or find a meetup a few weeks before your talk and give a shorter version of your talk. This is a great way to get feedback and refine your presentation.
Thank you
https://twitter.com/jr0cket
]]>